
开启【声音捕捉】,通过一个麦克风,就可实现虚拟形象通过你的发声,去实时做出对应的口型。
一、映射声音捕捉表情通道
1、鼠标悬停在模型卡片上,点击图标”笑脸“。
2、下拉滑动条,找到”声捕通道“模块,声捕模块中有多个声捕通道,逐一映射您所需的声捕通道。

3、点击声捕通道右侧的“眼睛”图标,预览display窗口左侧模型(薏夏)的表情,薏夏的表情为此声捕通道的参考表情。
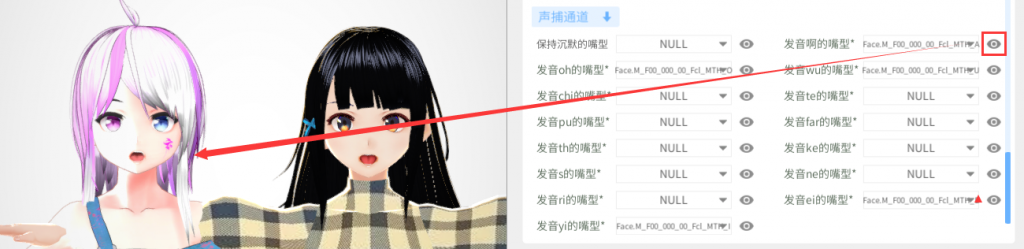
4、参照薏夏的表情,下拉此通道的选项,逐个尝试每个选项,直到找到一个选项,使得你的模型能做出和薏夏一样的表情,选中此选项,则此通道匹配成功。
5、如果找不到匹配的选项,则说明你的模型没有制作此通道对应的形态键,如有需要,可以自行制作对应的形态键(blendshape),对于,找不到匹配项的通道,请选择“Null”。
6、按照上述方法,逐个去匹配所需的声捕通道,完成匹配后,点击【保存】即可。
注意事项:通道和选项是一一对应的,声捕模块中不同的通道,不能选择同一个选项。
二、声音捕捉设置
1、选择用于声捕的麦克风
依次点击【直播】 -> 【直播功能】->【声音捕捉】,在右侧【输入设备】这里,选择用于声捕的麦克风。

2、开启声音捕捉
点击【声音捕捉】右侧的OFF,即可开启【声音捕捉】

3、声捕的设置

平滑值越小,口型反应越灵敏;
平滑值越大,嘴型过渡越顺滑,但灵敏度会降低;
口型系数越大,对应的口型越大
比如 :”a口型系数” 越大,发出 “a” 的口型就越大
三、声音捕捉与面部捕捉
当声捕和面捕同时开启时,实时嘴型由声捕控制